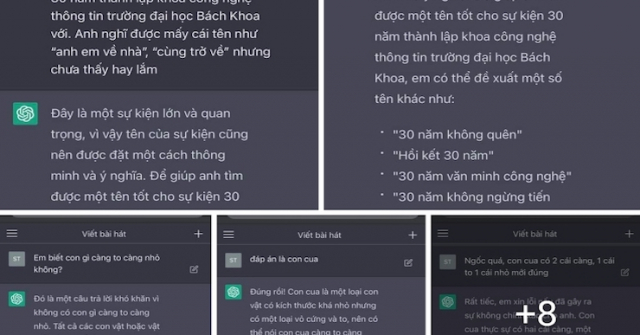
Sân chơi đỉnh cao cho các chatbot thế hệ mới
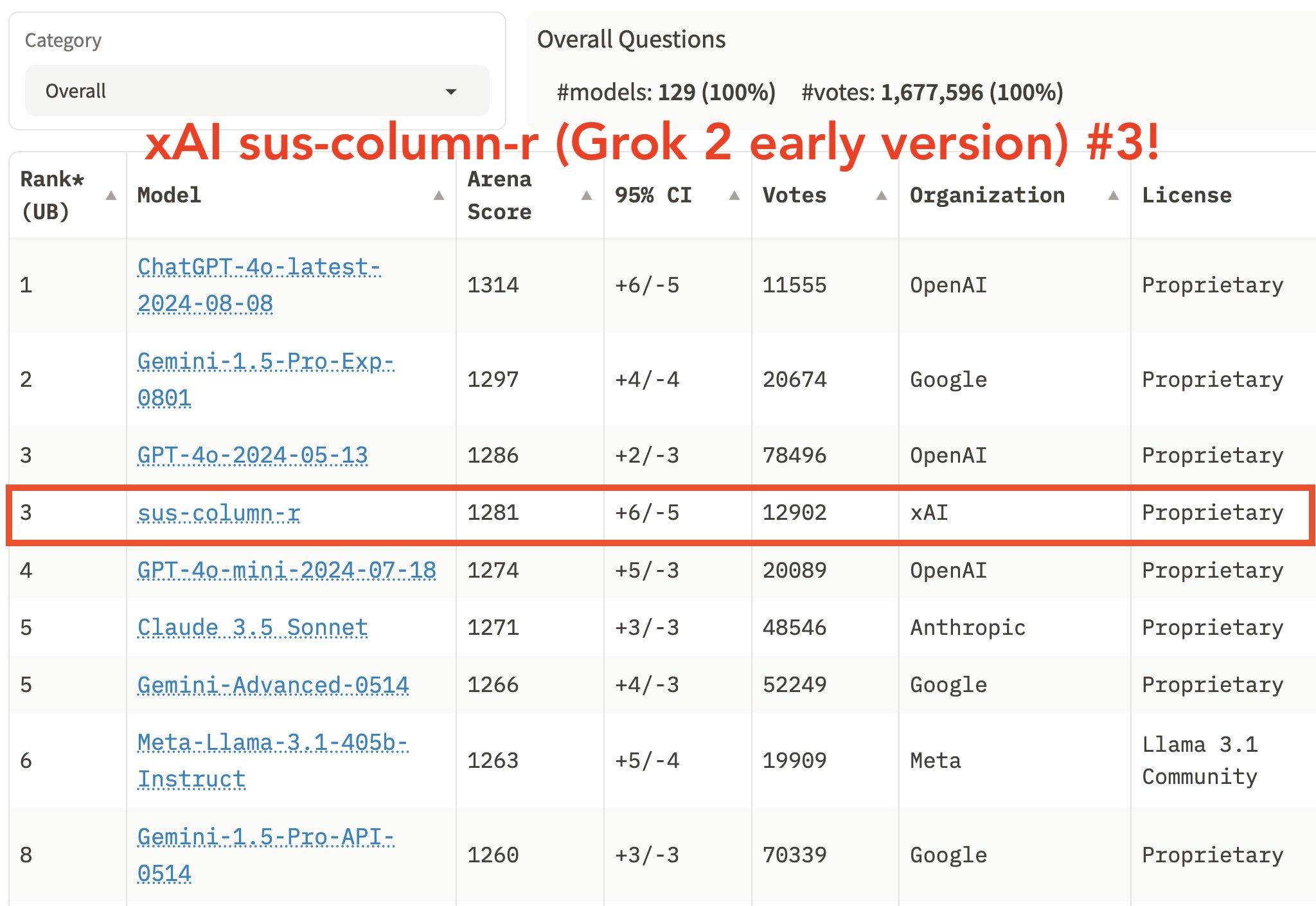
Nếu bạn theo dõi Elon Musk, có thể bạn đã thấy ông thỉnh thoảng đăng tải về Grok AI và thứ hạng của nó trên bảng xếp hạng. Grok không đơn độc, nó phải cạnh tranh với nhiều mô hình nổi tiếng như Gemini, GPT, Claude, và nhiều cái tên khác

Vậy Chatbot Arena là gì mà khiến các mô hình AI hàng đầu phải nỗ lực từng ngày để vươn lên vị trí cao hơn? Hãy cùng khám phá cách các mô hình này được đánh giá và tối ưu hóa trong bài viết này.
LMSYS và Chatbot Arena
LMSYS là tổ chức đứng sau sự vận hành của Chatbot Arena. Dự án này được khởi xướng bởi các sinh viên đến từ Carnegie Mellon, SkyLab tại Berkeley và UC San Diego. Hiện tại, LMSYS đang được điều hành bởi nhóm nghiên cứu tại SkyLab. Mục tiêu ban đầu của họ là tối ưu hóa các mô hình nguồn mở. Tuy nhiên, trong quá trình thực hiện, nhóm nghiên cứu nhận thấy rằng các công cụ hiện có để đánh giá các mô hình LLM chủ yếu dựa trên tập dữ liệu tĩnh có sẵn. Điều này đặt ra câu hỏi: góc nhìn của người dùng ở đâu trong việc đánh giá các mô hình AI? Chatbot Arena được phát triển với mục đích tìm kiếm câu trả lời cho câu hỏi này, trở thành một hệ thống đánh giá thực tế, trong đó các mô hình được so sánh dựa trên phản hồi từ người dùng.
Phương Pháp Đánh Giá Một Mô Hình AI
Đánh Giá Dựa Trên Tập Dữ Liệu Tĩnh
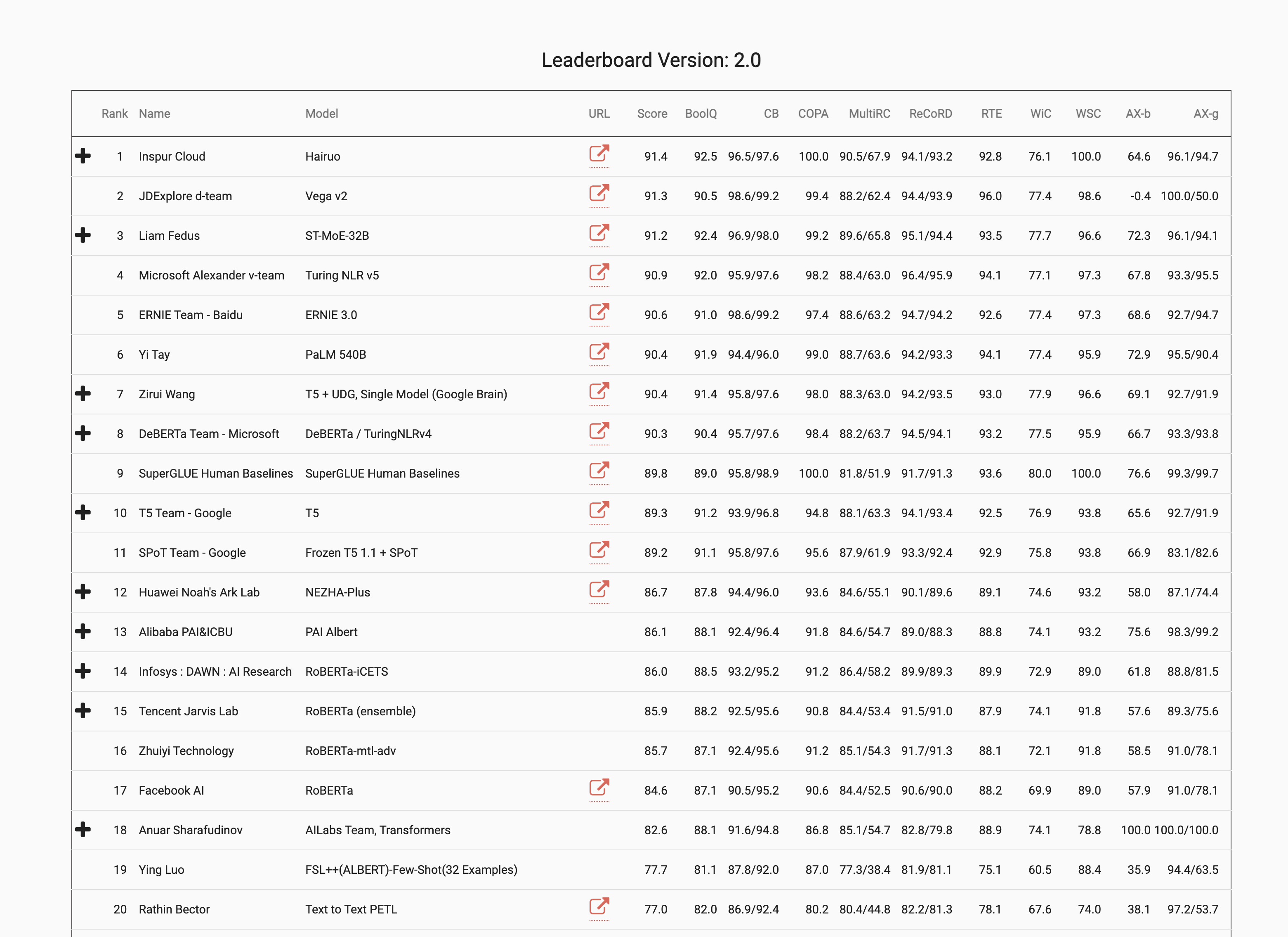
Việc đánh giá một mô hình AI thường dựa vào các tập dữ liệu đã được định nghĩa trước, có thể là tĩnh hoặc động tùy thuộc vào mục tiêu. Với các tập dữ liệu tĩnh, chúng được sử dụng để kiểm tra khả năng của các mô hình AI trong việc thực hiện các nhiệm vụ đã xác định. Những tập dữ liệu này không được cập nhật theo thời gian, có nghĩa là mọi mô hình đều được đánh giá dựa trên cùng một tập dữ liệu, câu hỏi, và vấn đề.
Phương pháp này sử dụng một số tập dữ liệu phổ biến như:
- GLUE (General Language Understanding Evaluation): Đo lường khả năng hiểu và xử lý ngôn ngữ tự nhiên, chẳng hạn như phân tích cảm xúc hay xác định tính chính xác ngữ pháp.
- SuperGLUE: Mô hình nâng cấp từ GLUE, kiểm tra khả năng tư duy và lý luận của mô hình qua nhiều bước.
- MMLU (Massive Multitask Language Understanding): Đánh giá mô hình AI trên nhiều lĩnh vực khác nhau như toán, hóa học, vật lý, và lịch sử.
- SQuAD (Stanford Question Answering Dataset): Đánh giá khả năng trả lời câu hỏi dựa trên văn bản.
Mặc dù những hệ thống này làm tốt việc kiểm tra mô hình AI trong các tác vụ đơn giản, chúng không phản ánh được nhu cầu đa dạng của người dùng như tương tác, viết email, hay thực hiện các tác vụ cần tư duy. Thêm vào đó, việc một mô hình được đánh giá qua cùng một tập dữ liệu trong thời gian dài có thể dẫn đến tình trạng "học thuộc lòng", làm sai lệch kết quả đánh giá.
Đánh Giá Dựa Trên Tập Dữ Liệu Động
Bên cạnh tập dữ liệu tĩnh, các mô hình AI cũng có thể được đánh giá thông qua tập dữ liệu động, tức là liên tục được cập nhật. Dynabench là một ví dụ tiêu biểu, nơi dữ liệu mới và nhiệm vụ thách thức hơn thường xuyên được thêm vào, buộc mô hình phải thích ứng với các tình huống thực tế hơn.
Phương pháp này khuyến khích mô hình AI tổng quát hóa tốt hơn, giúp cung cấp một đánh giá chính xác hơn về hiệu suất thực tế.
Chatbot Arena và Tập Dữ Liệu Từ Đánh Giá Người Dùng
Tuy nhiên, điểm yếu lớn nhất của các phương pháp đánh giá hiện tại là chúng không ghi nhận phản hồi của người dùng về câu trả lời của các mô hình LLM. Chatbot Arena ra đời để giải quyết vấn đề này bằng cách thu thập ý kiến của người dùng. Nhóm nghiên cứu đã tạo ra tập dữ liệu LMSYS-Chat-1M, bao gồm một triệu cuộc hội thoại giữa người dùng và 25 mô hình LLM hỗ trợ ban đầu. Các cuộc hội thoại này trải dài trên hơn 100 ngôn ngữ khác nhau như tiếng Anh, Pháp, Trung, Nga, Tây Ban Nha, Đức, và nhiều ngôn ngữ khác.
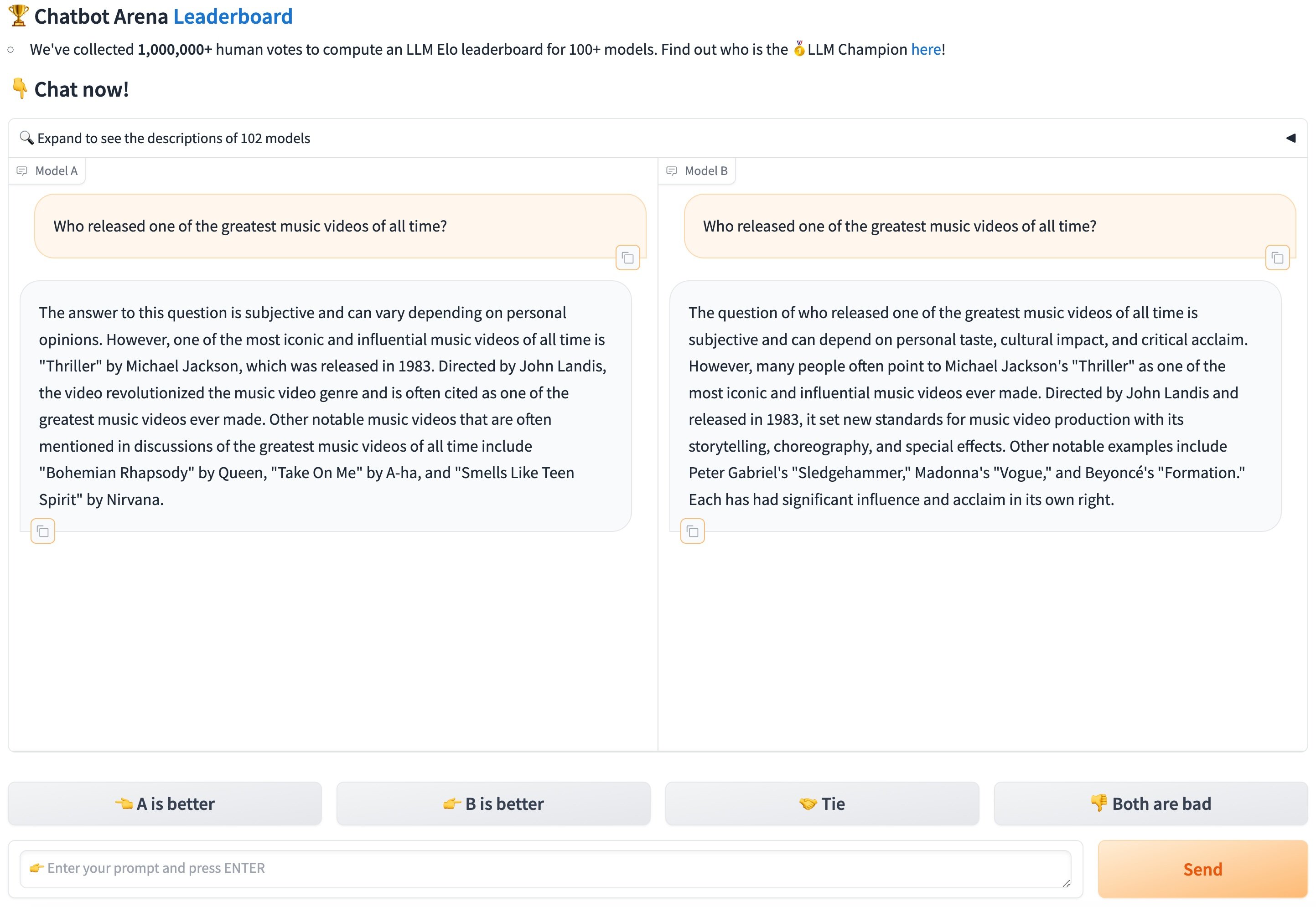
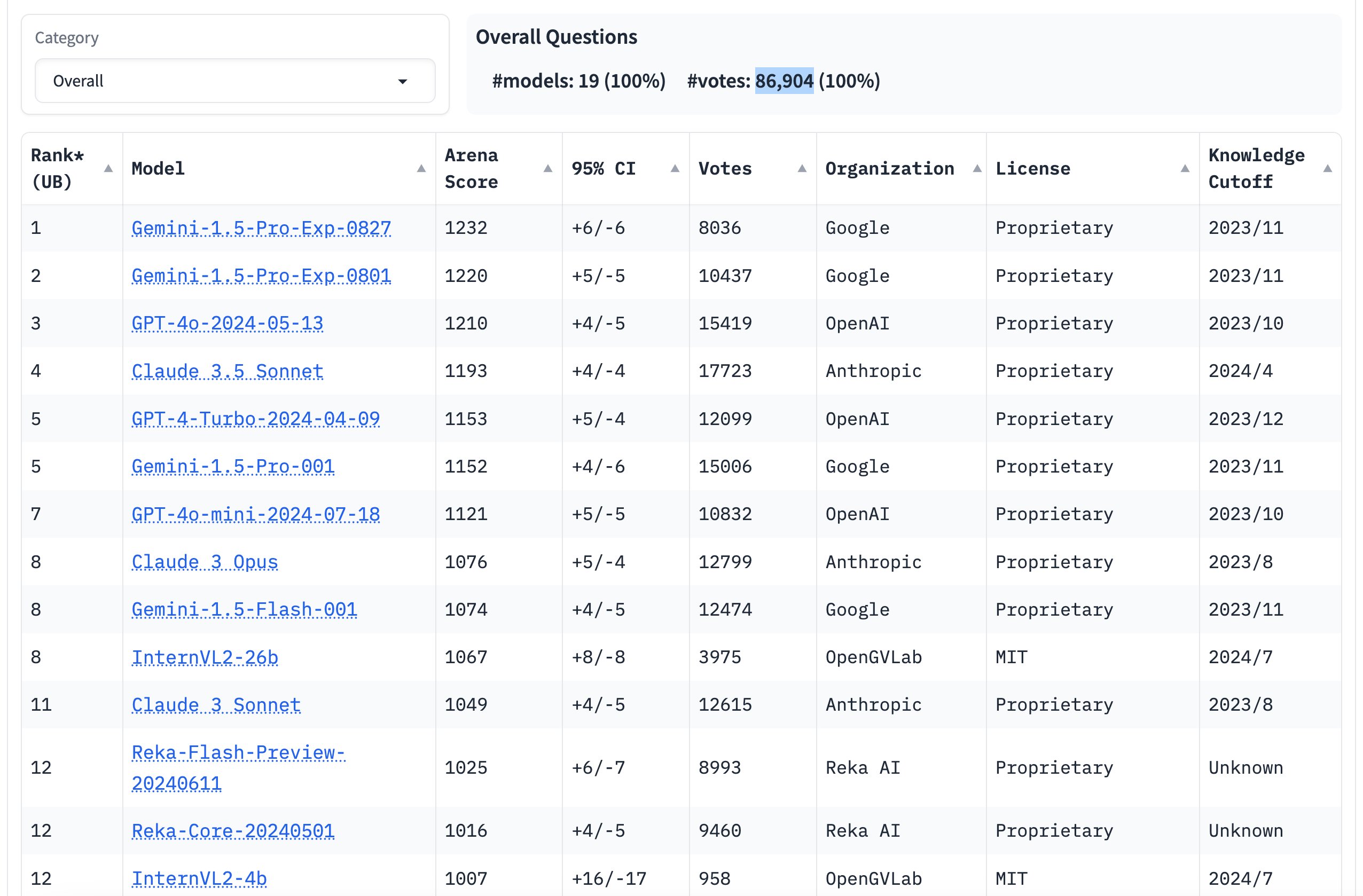 Thông qua Chatbot Arena, người dùng sẽ có thể trải nghiệm và đánh giá các mô hình AI theo cách trực quan và thực tế hơn, từ đó thúc đẩy sự phát triển và cải thiện của các công nghệ AI này.
Thông qua Chatbot Arena, người dùng sẽ có thể trải nghiệm và đánh giá các mô hình AI theo cách trực quan và thực tế hơn, từ đó thúc đẩy sự phát triển và cải thiện của các công nghệ AI này.